With Kubernetes, we can autoscale our resources natively with the Horizontal Pod Autoscaler. It works like a control-loop and queries some metrics. When it finds out that the queried metric is lower or higher than the threshold values we defined, it scales the resources up or down automatically. It does this by increasing the number of pods.
HPA works great with Cluster Autoscaling. When increasing the number of pods isn’t enough to compensate for the increased traffic, then scaling the infrastructure by increasing the number of nodes would work.
However, Cluster Autoscaler may not be suitable for every tenant/workload because Cluster Autoscaler is offered by Cloud Providers, it’s not a native Kubernetes resource. That is, this functionality is not available for on-premise environments because you don’t have on-demand resources as you do in cloud environments. That’s why I’ll be explaining the HPA for you in this article. We’ll first go into details of HPA and then continue with a simple demo that shows HPA in action.
How Does Horizontal Pod Autoscaler Work?
HPA scales the number of pods bound to a replication controller, a replica set, a stateful-set or a deployment based on resource metrics. In the first release (with apiVersion:
autoscaling/v1), these metrics were only per-pod metrics like CPU utilization. With the latest Kubernetes (with apiVersion: autoscaling/v2beta2 as of writing this) supports more options for metrics; per-pod metrics like Memory Utilization, Object metrics, or external metrics that can come from basically anywhere like Prometheus.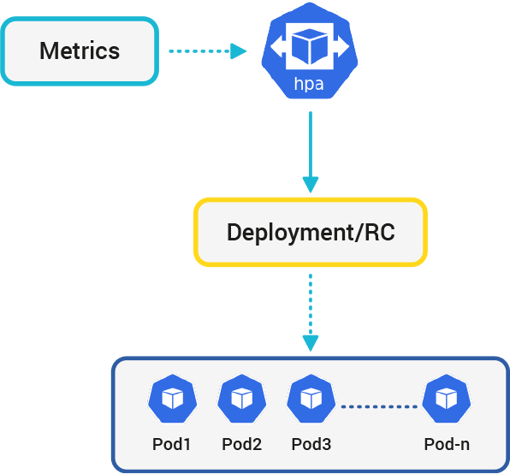
For example, if you pick CPU Utilization as a metric and pick %50, then HPA will query the CPU utilization periodically using the metrics server (which is 15 seconds default) through the controller manager. Whenever these queries show more than %50 CPU utilization, HPA will increase the number of pods to meet with the given CPU utilization.
When To Use Horizontal Pod Autoscaler
A more important question is when to use HPA rather than how. The most appropriate use case for HPA would be preventing down-time and performance problems caused by unexpected traffic spikes. If you define your pod’s container resource requests and limits the right way, then HPA would be perfect to use for these situations because it works better than manually scaling deployments.
However, if you have a planned event which will create a big traffic spike, scaling manually before that event would probably make more sense because HPA is not working super fast to compensate for traffic spikes. The reason is HPA’s cooldown period. After a scale-out or in event, HPA will wait for some time, and then if needed it will continue scaling your resources.
Demo
Let’s make a small demonstration to see HPA in action. For this blog post, I’ve written a small Node.JS server and dockerized it for Kubernetes.
To create the deployment and service for this demo;
- kubectl apply -fhttps://raw.githubusercontent.com/frknbrbr/node-hpa-manifests/master/node-hpa-manifests.yaml
- Now, let’s create a HPA;
kubectl autoscale deployment node-hpa --cpu-percent=50 --min=1 --max=10
- Alternatively you can create a HPA declaratively by;Creating a file named “hpa.yaml” and adding;
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: node-hpa spec: maxReplicas: 10 minReplicas: 1 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: node-hpa targetCPUUtilizationPercentage: 50
- kubectl apply -f hpa.yaml
- kubectl run -it --rm load-generator --image busybox -- /bin/sh
- while true; do wget -q -O- http://node-hpa:3000; done-
- kubectl get deployments
- kubectl get pods
- kubectl describe hpa node-hpa
After seeing that our deployment is scaled, we can remove the load generator by stopping the command on the load-generator pod.
Because of the cooldown period of HPA, the scale-in activity will probably take more time. After that, we’ll see that our deployment is scaled-in and the number of pods is decreased to the necessary amount.
Conclusion
In this blog post, we’ve seen what HPA is and it behaves. We have seen what HPA does for our scalable resources (which can be deployments, replica sets, replication controllers, and stateful sets) and how it increases or decreases the number of pods by comparing current metrics with given thresholds.
We covered use cases to use HPA and then did a small demo to see HPA in action. We reviewed scaling events with using kubectl.
