Challenges of scaling Microservices
Internet data and traffic grows exponentially day by day, not linearly. An application may not be able to cope with the increased load even if it is handling the traffic successfully today. The most commonly used methodology to manage the ever-growing pressure is application scaling. Scaling is done in two different ways, vertical scaling and horizontal scaling[1]. Vertical Scaling means adding more resources (CPU, memory) to the existing monolith application. Horizontal Scaling, on the other hand, is adding more nodes to a system providing additional resources. Horizontal Scaling also increases fault tolerance and provides high availability. Note that horizontal scaling is preferred in microservices architectures because of its lower cost. However, achieving these benefits do come with challenges:
- Data decoupling
- Caching data
- Fault tolerance between services because of the interdependence of services
- Monitoring and troubleshooting the business flow which is challenging with modern infrastructure monitoring tools in a distributed environment
- Dealing with networked, shared, multi-resource data management in business critical operations (i.e. transactions in monolith architectures)
The list can be longer depending on where you are in the process of adopting a microservices architecture. In this paper, we present you with solutions to these problems with our Event Sourcing implementation and with the help of distributed cache and computing features from Hazelcast IMDG.
1.2 Choosing Eventual Consistency
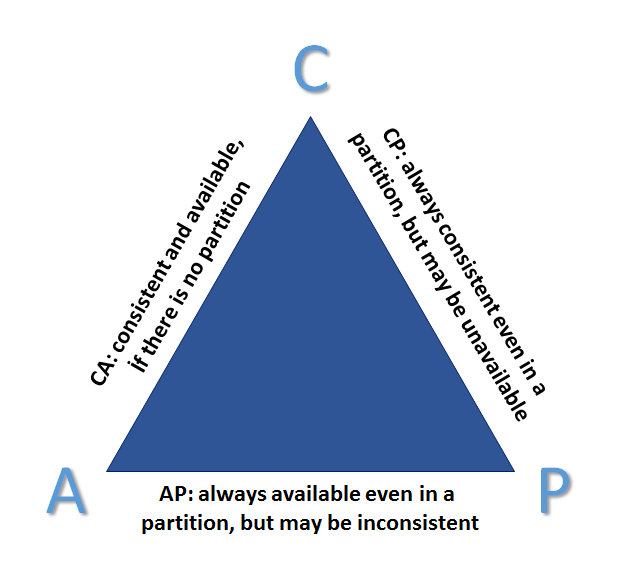
When dealing with a distributed architecture such as the networked, shared, multi-resource system that we are proposing, it is essential to recognise the common pitfalls of these systems. According to CAP Theorem[2], it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees: Consistency, Availability, and Partition Tolerance.
Since we have a distributed architecture, Partition Tolerance is given. That is to say; partitions are inevitable facts of distributed systems. Thus we cannot give up Partition Tolerance. So, the actual selection is between Availability and Consistency. Availability with Eventual Consistency is a preferred choice against strong consistency in most distributed systems if the system needs to be highly available.
Eventual Consistency[3] is a method of consistency which informally guarantees that, if no new updates have been to a given data item, eventually all accesses to that item will return the last updated value.
To understand what we mean by eventual consistency and strong consistency, let's consider the example of money transfer between two accounts. When these accounts are situated in the same bank, usually a transfer within them is immediate and consistent across these two accounts. However, if you are transferring money from Wells Fargo to Commerzbank, then you see the money subtracted from Wells Fargo account and not yet added to the Commerzbank account. Usually, it takes a couple of business days for the money to show up at your Commerzbank account. Of course, banks provide every kind of logs so that money can be recovered if something goes wrong, but if you observe the external state of the system, you notice that the sum of two accounts is not immediately consistent.
The choice of eventual consistency brings us the cost of migrating from classical ACID[4] systems which guarantee the strong consistency to BASE[5] systems which in turn offers eventual consistency.
In this manner, since Hazelcast IMDG offers AP (eventual consistency) with best effort Consistency, we have quickly adopted our components inside our architecture with ease.
1.3 Why Event Sourcing?
When dealing with a distributed microservice architecture, the challenges of decoupling data and multi-resource data management require particular attention.
Traditional monolith applications that use external resources rarely work on ACID databases to achieve consistency by doing Transactional Resource Management. In the case of having external resources, the consistency is reached by synchronizing (process/commit/rollback) with the existing transaction context in the best way possible. With the monolith to microservice transition and polyglot persistence[6], regardless of whether they are internal or external, all the resources would be external to each other. So the problem of assuring consistency among several resources/databases/systems arises. One solution might be 2PC (two-phase commit) strategy. However, since 2PC requires locking all the resources inside the transaction context, and the main idea of having microservices is to achieve maximum scalability and interdependence of components, managing multi-resource data operations with 2PC strategies would not be an efficient solution.
Also, when working on resources that have CRUD (Create / Read / Update / Delete) operations we have realized that designing resources with CRUD operations does not solve all of our problems. The operations on the entities are the results of the work-related events, not the CRUD operations.
A solution to the challenges above is storing all the events operated on the entity instead of storing the latest snapshot. This method is called Event Sourcing, and it helps us to establish eventual consistency between multiple resources.
With event sourcing, we can build entities by aggregating the events occurred instead of reading one row from the traditional ACID compliant database. Also, we can capture the state of an event where some of the events rolled back or failed. That is to say; an entity can provide us with an Eventual Consistent structure in a distributed microservice architecture when it can be expressed as the sum of events (i.e., aggregates) that can be reconstructed, rather than a data line.
[Image: Microservices - Event Sourcing]
1.4 CQRS
When we transform our applications from CRUD to event-based architecture, we face some changes. We will no longer have the CRUD resources. We need to solve the questions of how to read the data and how to take action/change an entity in this manner.
Command Models take actions on entities and change their states, and View / Query models collect and aggregate the events on the resources to read, help us solve this question. These command and query models can also reside in different microservices even if they represent the same resource. This way of representing data is called Command Query Responsibility Segregation (CQRS). CQRS can also be implemented in CRUD based architectures as well, but it eases event-based architectures more.
[Image: Microservices - Command/Query]
As examples of commands and queries, think of a stock resource. (was a Stock table in traditional architecture) All the read operations of a particular stock item or reading bulk of stock items would be queries. Also, all the write operations like increase stock and update price, that change the state of a particular item would be considered as commands.
2. How to ease Event Sourcing/CQRS with Hazelcast IMDG
2.1 Event Sourcing/CQRS challenges
Since nature of Event Sourcing/CQRS is different than classical CRUD based single RDBMS transactional systems, we have to plan and resolve concepts below carefully. These concepts may produce thought challenges while implementing microservice based systems if we are not aware the nature of Event Sourcing/CQRS. Let's look at these:
2.1.1 Commands/Entities
Generally, in monolithic applications, we may have Entities and CRUD operations. When we need to change multiple entities atomically, we just use Transactions. However, in systems which use Event Sourcing/CQRS, we have Commands instead of CUD (create/update/delete) and Query for R (read). Also, Commands do not need to operate over Entities; they may operate against Aggregates.
2.1.2 Event Store
Instead of storing Entities, we have Events. We might need to access events to do operations. In traditional architectures, we can run index by entity fields, join and query these entities. However, now we have events stored in Event Store. Each event may contain data and affect multiple entities.
2.1.3 Query Functions
After storing events, our system must respond queries. Queries can target a single Entity (yes lots of development still needs entities) or view (joined and filtered version of entities). Queries consist of functions which convert Events into these Entities or Views. However, only one row of entity or view might require an evaluation of thousands of events.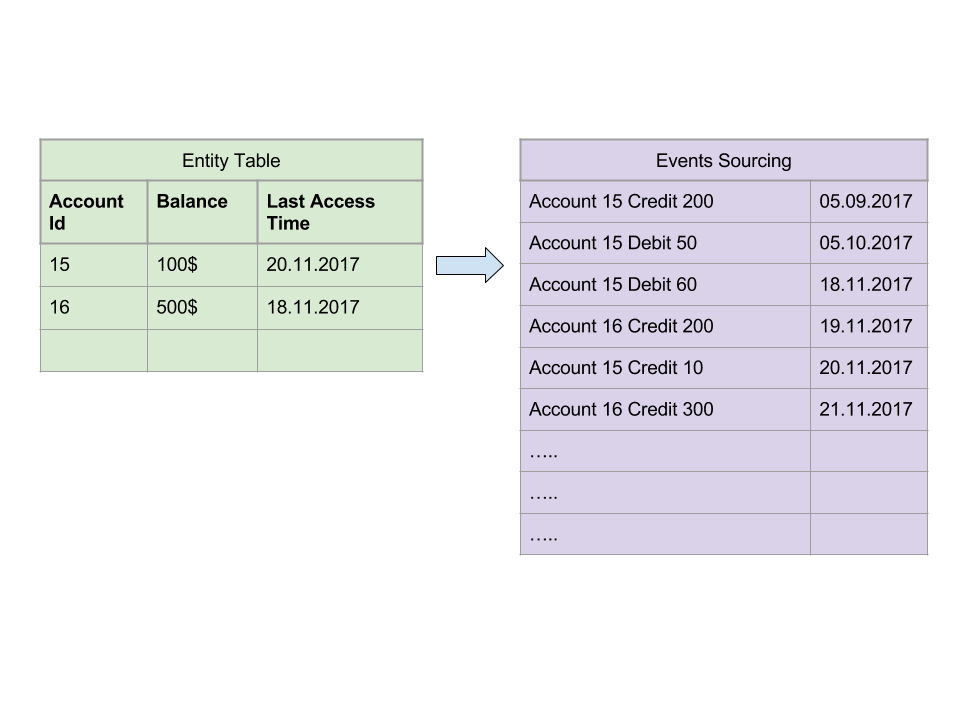
[Image: Account Balance, Entity - Events Deconstruction]
For example, as you see above, we have deconstructed Account Balance into Events, one of Balance may contain thousands of operations (Credit/Debit). Complex queries like joins and aggregates can also include multiple records of Customer Balance. So this is one of the challenges, we have to solve it to apply Event Sourcing/CQRS on our microservice architecture.
[Image: Multiple Events - Entities-Views etc Query Side problem]
2.2 Solving Query Side problems with Hazelcast
2.2.1 Replays, Snapshot States, Versions
Snapshot concept has been introduced to solve query side problems. We are persisting previous State of Entities or previous Result of Queries. When we need the latest state of Entity or Query Result, we just need to apply most recent events to the previously recorded state.
[Image: Multiple Events - Snapshot]
To efficiently apply Snapshot strategies, we need to answer some questions:
- Should we persist all snapshot states (after each event)? Alternatively, can we keep only latest states?
- Do we need a persistent store to keep all rows? We have already recorded events as Single Source of Truth. We may have a lot of Entity/Query definitions.
- Since snapshots are only performance helpers, how can we implement proper housekeeping strategies?
- Query Functions are code fragments tied to events. How can we cache and keep versions of these?
[Image: Multiple Events - Entity/Query Snapshots]
At this stage, Hazelcast IMDG comes into help. Since we have persistent Events as Single Source of Truth, we can build Snapshots in memory and use calculated states in a distributed scheme. Hazelcast can help to scale quickly with functionalities below:
- Calculate snapshots, updates to newer states. Also, with Entry Processors, we can eliminate recalculations.
- We can store these Snapshots in memory, especially High-Density Memory Store can help us keep the larger size of Snapshots with reduced garbage collections (GC).
- Expire/Evict old or low priority Snapshots with various policies to make housekeeping.
[Image: Entity/Query Snapshots]
[Image: Entity/Query Snapshots - Hazelcast Usage]
- Additionally, we can keep Query Functions with Hazelcast User Code Deployment. So Any Query Service can answer, and we can easily define/cache/change query functions without restarting Query Microservices
[Image: Entity/Query Snapshots - Hazelcast Usage - User Code Query]
2.3 Solving Monitoring Problems with Sliding Windows
- In general, Event Sourcing/CQRS is not a standardized way to implement Application Stacks. Common Monitoring/Tracing tools are designed to integrate common Request/Response protocol stacks with CRUD operations over RDBMS/NoSQL. Moreover, it is hard to see desired Command/Event workflows with these tools. We can still monitor/trace microservice per Event or Request, but it is hard to see the effect of Commands and Query calculations. We need helper technologies to integrate Event Sourcing/CQRS into common Monitoring Stacks.
- Event Sourcing requires microservices to communicate through Events. External Commands can produce many events through different microservices. Also, in case of unexpected failures, we do not have timeouts(such as socket-read timeouts, connection errors in Rest) or auto-rollback features(RDBMS rollbacks). So we need some Monitoring/Guardian processes to keep Event Sourcing/CQRS based systems healthy and consistent.
2.3.1 Request Tracing
After we receive the command, we can collect event generation and handlings. So we may generate topology for each Request(in CQRS, Command). Generating topology helps to monitor Microservices with providing better information for Operation Boundaries for Commands. We cannot keep all information for every command and events, and we have to track in the specific time window. With the help of Hazelcast IMDG:
- We can implement these type of Processes which handle events and provide Tracing information
- We can scale these processes thanks to Hazelcast. Tracing information must keep in memory and automatically expire/evict after required time window.
[Image: Eventbus, Request Tracing with Hazelcast]
2.3.2 Timeouts, Error Handlings
If we listen Eventbus and keep the current state of Command Operations, we can track timeouts and unexpected failures of microservices. When a microservice dies after receiving event or stuck, we have to generate Control events to help other Microservice to decide what to do next (retry/rollback, move forward, etc.). Together with Tracing information mentioned in 2.3.1, we can generate additional Control events. In this context, Hazelcast can help to:
- Keep current state of Command Operations till finish. We can access Operations very fast when needed.
- Issue Control Events(based on Scheduling or Eviction) and atomically update the state of operations(Entry Processors).
[Image: Eventbus, Error Handling]
2.3.3 Event Dispatching
CQRS means Command and Query are separated from each other. A successful response of command only implies that system started to operate your request. We have to query or watch specific events to know we reached the desired state(success or fail). However, at the moment not all of the development components may act like that.
For example, websites may want to keep the user in processing screen after issuing Command. In these type of scenarios, other systems can u occasionally query the desired state of operation. However, we cannot open whole Events/Queries to these systems. With the help of Hazelcast:
- We can keep filtered events as a result of Operation. So these systems can query or consume results.
- We may apply different filtering/eviction policies, or we can keep events related to operations only some systems want to dispatch.
- With Security Features, we can Authorize external systems to access only permitted events/results.
[Image: Event Dispatching with Hazelcast]
3. Conclusions
As a result, Hazelcast IMDG provides indispensable memory functionalities to meet the required maturity level of Event Sourcing/CQRS architecture in Enterprise Applications.
- Queries: High-Density Memory Store, Entry Processors, Expire/Evict
- Request Tracing: Expire/Eviction
- Error Handling/Timeouts: Scheduling, Eviction, Entry Processors
- Event Dispatcher: Security Features
bove are critical areas of Hazelcast IMDG which we use in our Event Sourcing/CQRS solution called Eventapis[7]. To be continued with applied code samples...
[1] Scaling: https://en.wikipedia.org/wiki/Scalability
[2] CAP Theorem: https://en.wikipedia.org/wiki/CAP_theorem
[3] Eventual Consistency: https://en.wikipedia.org/wiki/Eventual_consistency
[4] ACID: https://en.wikipedia.org/wiki/ACID
[5] BASE: https://en.wikipedia.org/wiki/Eventual_consistency
[6] Polyglot Persistence: https://martinfowler.com/bliki/PolyglotPersistence.html
[7] Eventapis: https://github.com/kloiasoft/eventapis