In this blog post, I will explain the pattern called Strangler Fig, which became popular for splitting the Monolith. I will try to address how AWS services can facilitate this during the AWS MAP (Migration Acceleration Program) Modernization phase.
Before going deeper, let's remember the phases of AWS MAP:
- Assess
- Mobilize
- Migrate&Modernize
In this article, I will be focusing on the “modernize” part of the last phase. The modernization phase is usually suggested after migrating to AWS. Considering the “do one thing at once” principle, it’s acceptable first to concentrate on “just” migrating, which is also referred to as “Lift&Shift”. Although this is the desired path, we have experienced that certain companies are unwilling to progress with “Lift&Shift” on their legacy on-premises infrastructure. There may be several reasons for this:
- On-premises infrastructure may possess several operational risks related to missing know-how over the years, which makes it risky to migrate.
- Insufficient or missing documentation
- The current on-premises licenses are not allowed to run on the cloud or are not supported by AWS BYOL.
- Financially, the on-premises investment amortization period still continues.
Those companies are still willing to adapt to cloud services, but only for their modernized workloads.
MAP Assess and Mobilize phases are positioned to decide on a migration strategy and address solutions for all technology-wise or cost-wise concerns.
So far, we have discussed two types of companies with different approaches and strategies for the MAP:
- Migrating to AWS and then Modernize
- Migrating only the modernized workloads.
Let’s assume the customer is convinced with the MAP offering, and the migration phase is finalized. Now we are focusing on modernization. Although there may be several aspects of modernization, in this article, as I mentioned, we will focus on “Strangler Fig”, which is used for “Splitting the Monolith”
|
Monolithic software can be defined as referring to the applications using a single central relational DB(Database), where a bounded-context or domain can directly access the data of the other domain. |
As most Monolithic applications have an existing RDBMS Database, and there are existing relations between the tables. Here is a real-world example of the relations between the tables of a real-life project: (Each dot represents a table, and each line represents a relation)

Comment below which table is easier to split?😀
Our complexity is not only the relations but also the different pieces (Bounded Contexts) of the software that are currently accessing the data of another piece directly by executing SQL queries or SPs(Stored Procedures).
Our mission is to split a bounded context from that Monolith. You may already have heard about the Strangler Fig pattern, where there are several articles around it.
|
Strangler Fig defines a pattern where you split the pieces of software one by one and redirect the traffic to the split pieces. The splitting continues until all pieces are done, and the Monolith fades away. |
The common articles around the Strangler Fig pattern are usually explaining the standard definition of the pattern but do not suggest to you a solution regarding the data dependency I have defined above regarding the table relations and domains accessing the data of the other domain. AWS Migration Hub Refactor Spaces also helps you to apply the Strangler Fig pattern by orchestrating AWS Transit Gateway, VPCs, AWS Resource Access Manager, and AWS API Gateway but does not address a solution regarding the dependency on the split data of the existing legacy. Let me try to explain this problem in more detail:
Consider you have split a piece from the Monolith to an external independently deployable microservice, and you have redirected the requests coming to that piece on the API Gateway with URI path-based routing. We have been in parallel with the Strangler Fig, but in reality, this will not work most of the time. BUT WHY?? Consider the bounded context you have splitted is generating data(This data is now on the new database of the splitted microservice) which the other bounded contexts should also consume. And naturally, the other bounded contexts may be expecting this data on the existing Monolith Database tables. You may argue that we need to refactor the existing bounded contexts so that they query to the API rather than querying the Database. In such a situation, it is usually advised to refactor the affected bounded contexts, but you may experience a high cost doing that.
So you are your own to find a solution! I will be suggesting some alternative solutions to address this data dependency.
Before joining in deeper, Event-Driven or/and Event Sourcing approaches are not in the scope of this article. The reason is those probably will need relatively major refactoring on the existing software architecture.
Let’s assume there is no “Event-driven” architecture in place. There may be several solutions to address the data dependency problem of the legacy software on the legacy database. First, I will discuss the approach called "Parallel Run", which means calling the legacy and the new split API microservice simultaneously. We can achieve this with the following techniques:
1- AWS VPC traffic mirroring:
The purpose of this feature is not tailored for Strangler Fig but potentially can be used for that purpose.
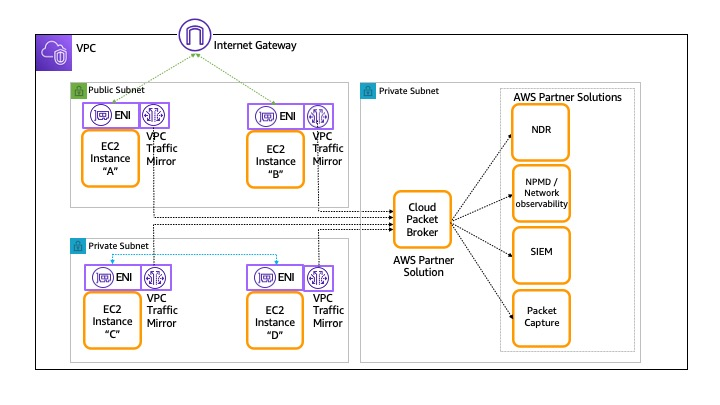
Here is how to create the mirror traffic on AWS:

2- API-Gateway level Traffic mirroring:
Current AWS API Gateway does not support mirroring, but alternative API Gateways can be used for mirroring
3- Service Mesh level traffic mirroring:
Istio service mesh has mirroring capability.
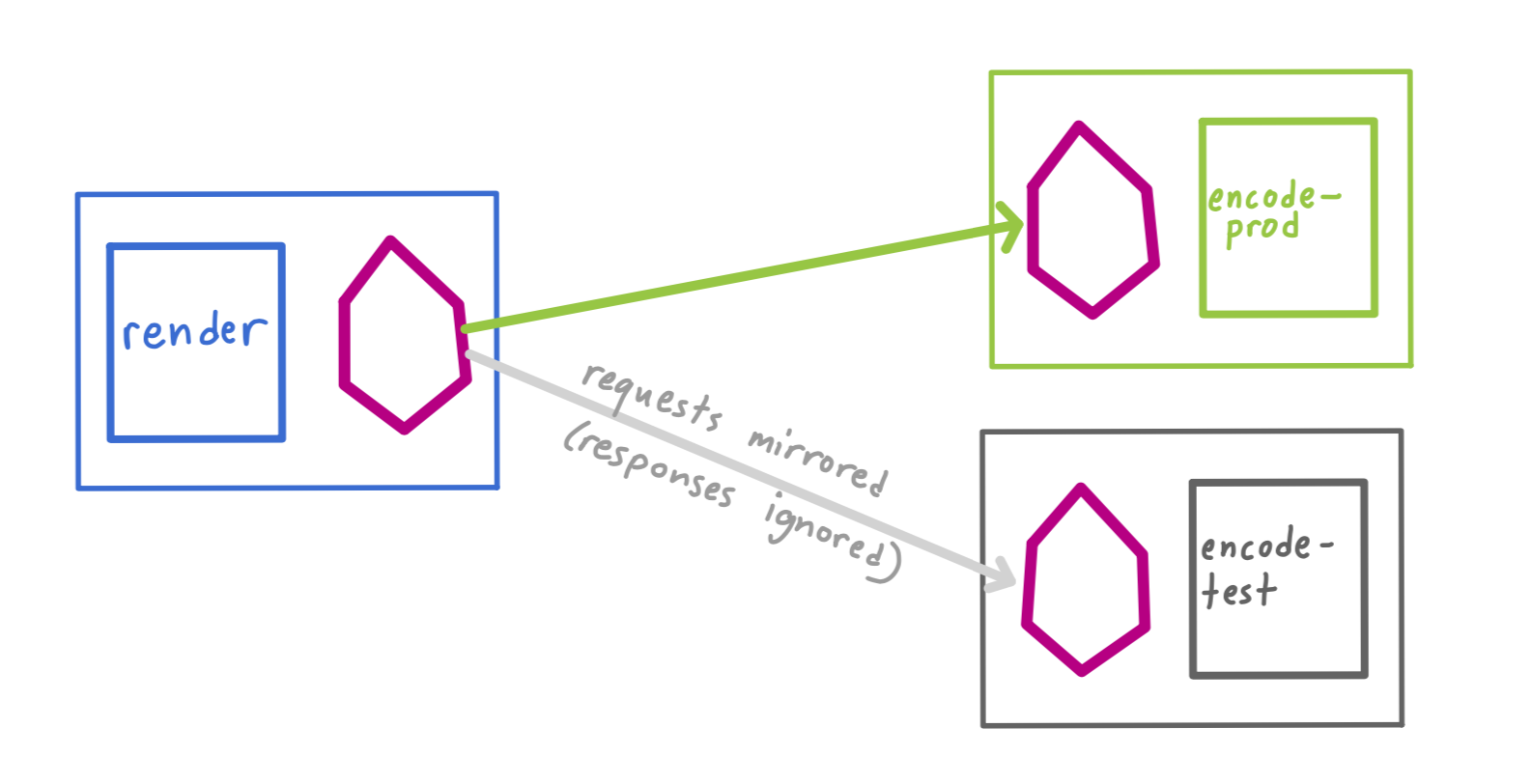
Ref: https://istiobyexample.dev/traffic-mirroring/
As you can see, mirrored traffic responses are ignored. Guess what type of risks this architecture has? (Comment please if you have found any)
What may be the downside of this approach? I can feel you are saying “rollbacks”. In case the HTTP response from the legacy and the new microservice is not the same (one is HTTP 200 and the other is HTTP 5xx), in such cases, we may need to roll back the one with the HTTP 200 response.
If you see risks related to “Parallel Run”, it is possible to begin your splitting journey by “Dark Launching” your splitted microservice, mirroring the traffic but keeping that domain in a passive state until you get satisfied with the results.
Let me also suggest another alternative solution from a data consistency perspective. Each application running on the Database may not have the same data consistency requirement. The nature of some applications may be more tolerant of data inconsistency between the bounded contexts. Let me elaborate on this with some examples:
- An order of the customer does not necessarily be on the Backoffice/Warehouse application in real-time. Until the data of the order is synchronized with the warehouse applications database, there is data inconsistency, and the business accepts this delay.
- The splitted microservice is responsible for the SMS operations and keeping the status(sent/failed/error) of the SMS sent to the customers. The status of the SMS is also used by another bounded context(domain), but this domain is expecting the status of the SMS on the existing Monolith Database. This domain may be tolerant to seeing the status of the SMS in delay.
If the application is tolerant to such inconsistencies, there may also be another solution to keep the Monolith Database and the new microservice Database in sync. Using AWS DMS, you are able to define source and target databases, together with what type of changes to synchronize. Here are some screenshots from AWS DMS:

As you can see, DMS is limited to RDS2RDS or Mongo2DocumentDB. This may not be what we are looking for in a real-world scenario. If the splitted microservice would have a DocumentDB, in such case, DMS would not work. As an alternative, Debezium can be positioned in such a situation:

As I initially mentioned in this article, I have not referred to an Event-driven approach architecture to solve the problem. This is not because I am against it, but it is a separate topic and needs to be in a separate blogpost. Maybe next time:)
In conclusion, if you decide to split your Monolith, referring to the Strangler Fig pattern, consider how to solve the data consistency and dependency in case refactoring the monolith has a high cost. I have provided some options without implementing an event-driven model.