There are many branching strategies to apply in your development, like Trunk Based Development, Feature, or Environment branching. Generally, the Trunk Based Development and feature branching strategy are use more than other strategies. Trunk Based Development may be a good choice in some cases. For example, if your code is made of completely independent components, little to no dependencies, and not being worked on concurrently by multiple developers, Trunk Based Development works well in these cases. So let's think like this, there is a development team, it's so crowded and there are so dependent codebase each other that the team's members can be committed on the same lines and in this case, conflicts are seen.
But, Trunk Based Development is insufficient in some cases. For example, a developer wants to release their work on an issue, but there are other incomplete fixes in a trunk main. This means that the incomplete fixes will be included in the release, which is not what we want.
The other branching strategy is Feature branching. The Feature branching strategy can not be used to solve these conflicts. Because Issues will be defined as branches in the Feature branching strategy, and they are separated from each other. When issues are merging, conflict may occur, and this conflict will be visible when issues merge. However, it will be a long time until these issues conflict, so it will be too late to find a fix that combines these issues. Therefore, the release will be delayed. Another problem is so much cost when working with feature branching strategy at the containerized infrastructure. Because feature branches must be deployed to testing in the cluster. This implies more containers and more resources.
We have encountered all variations of these cases in our clients. To address these, we created the Adaptive branching strategy. Adapting branching makes it possible to have concurrent development while making conflicts visible earlier and helping teams avoid releasing incomplete issues. It addresses the problems above along the software deployment pipeline, such as code merging, feature toggling, and cost optimization, which has a use case, especially on distributed software architectures.
What is Adaptive Branching?
Adaptive branching is a pattern that proposes a model where Trunk-based Development cannot be applied in certain conditions. This pattern is supposed to integrate feature branches in an adaptive branch(like a trunk). The Adaptive branch is a copy of the main branch and helps in testing. After the Adaptive branch merges tested codes to the main branch and releases issues.
The cornerstone of this pattern is the frequent synchronization of distinct branches on the version control systems. So, the adaptive branch is created with merged distinct branches. This synchronization is provided with some git and bash commands.
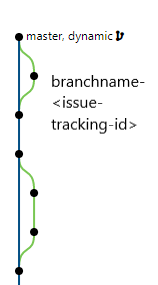
Developers create a feature branch with the same name that the issue on the issue tracking system. After that, when the development stage has been completed, the feature merges to the dynamic branch. So, The branching tree structure will be like the right side pic.
Adaptive branch pattern steps can see below;
Model Steps
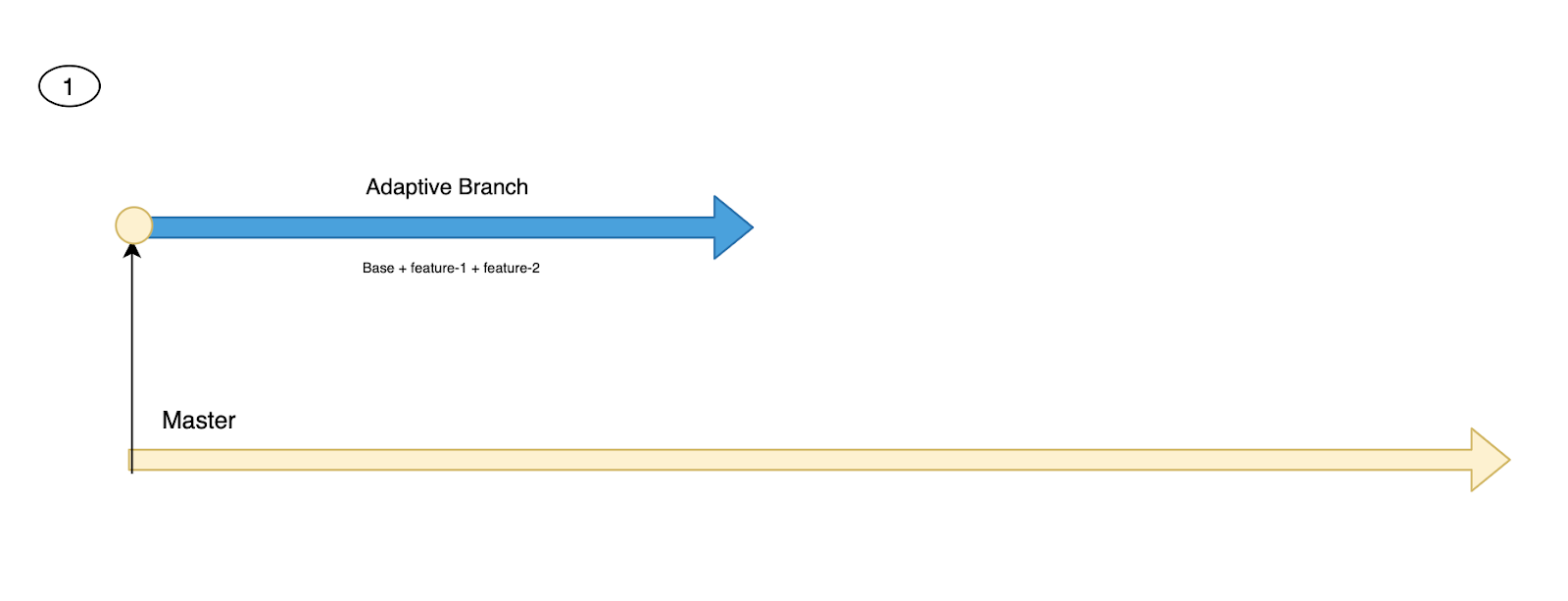
Step 1: Adaptive branch pulls the master branch. The main purpose of this step is to be in sync with the master branch.
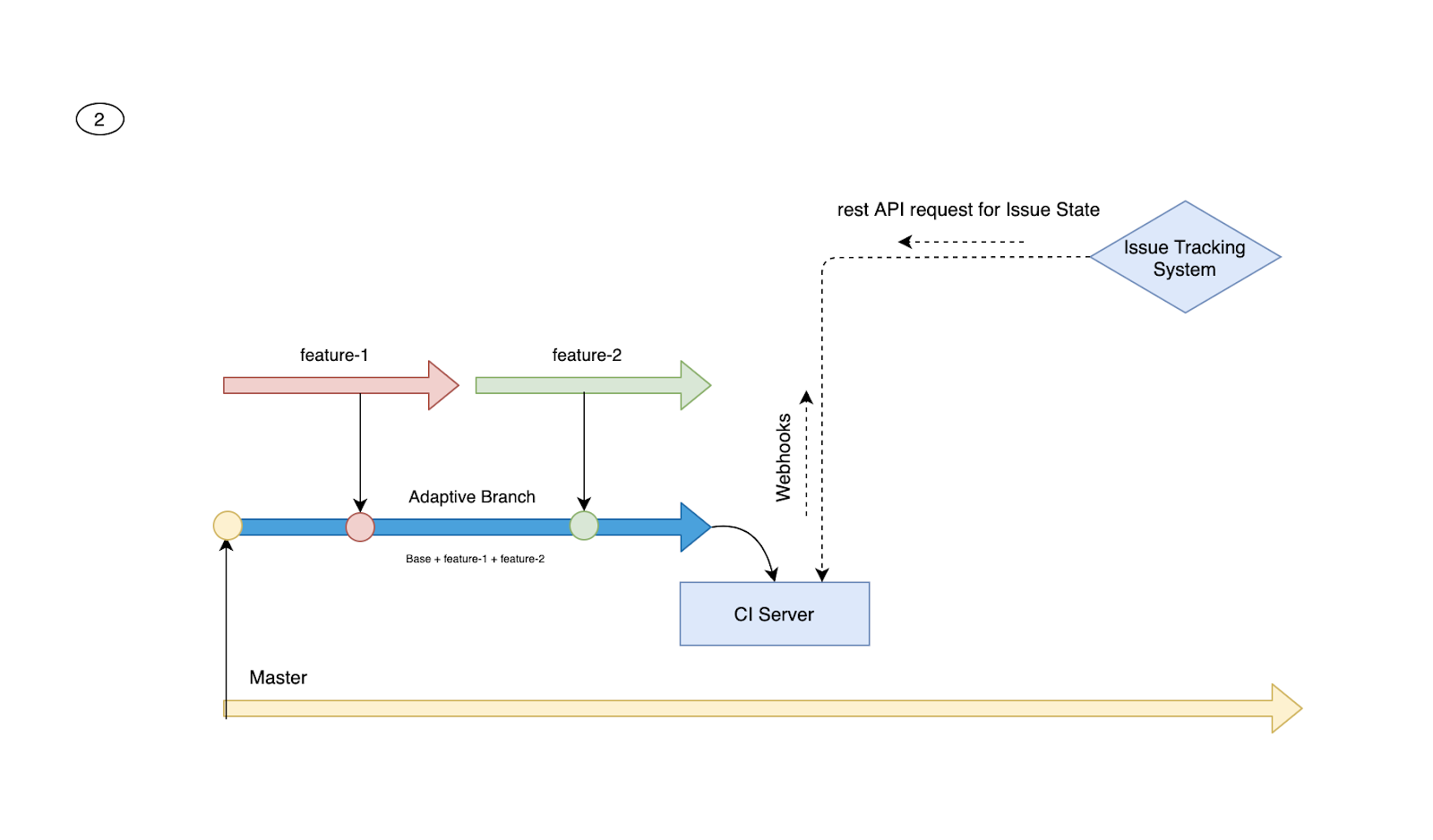
Step 2: In our model, feature branches are merged to the adaptive branch with webhooks at the issue tracking system by a Continuous Integration Server only if the following conditions are valid:
- The feature Branch name is the same with the Issue name
- Issue state is “In Test.”

Step 3: Continuous Integration Server triggers a build on Adaptive Branch. In case of the build finishes successfully, version control commitID is given to the artifact as version reference.
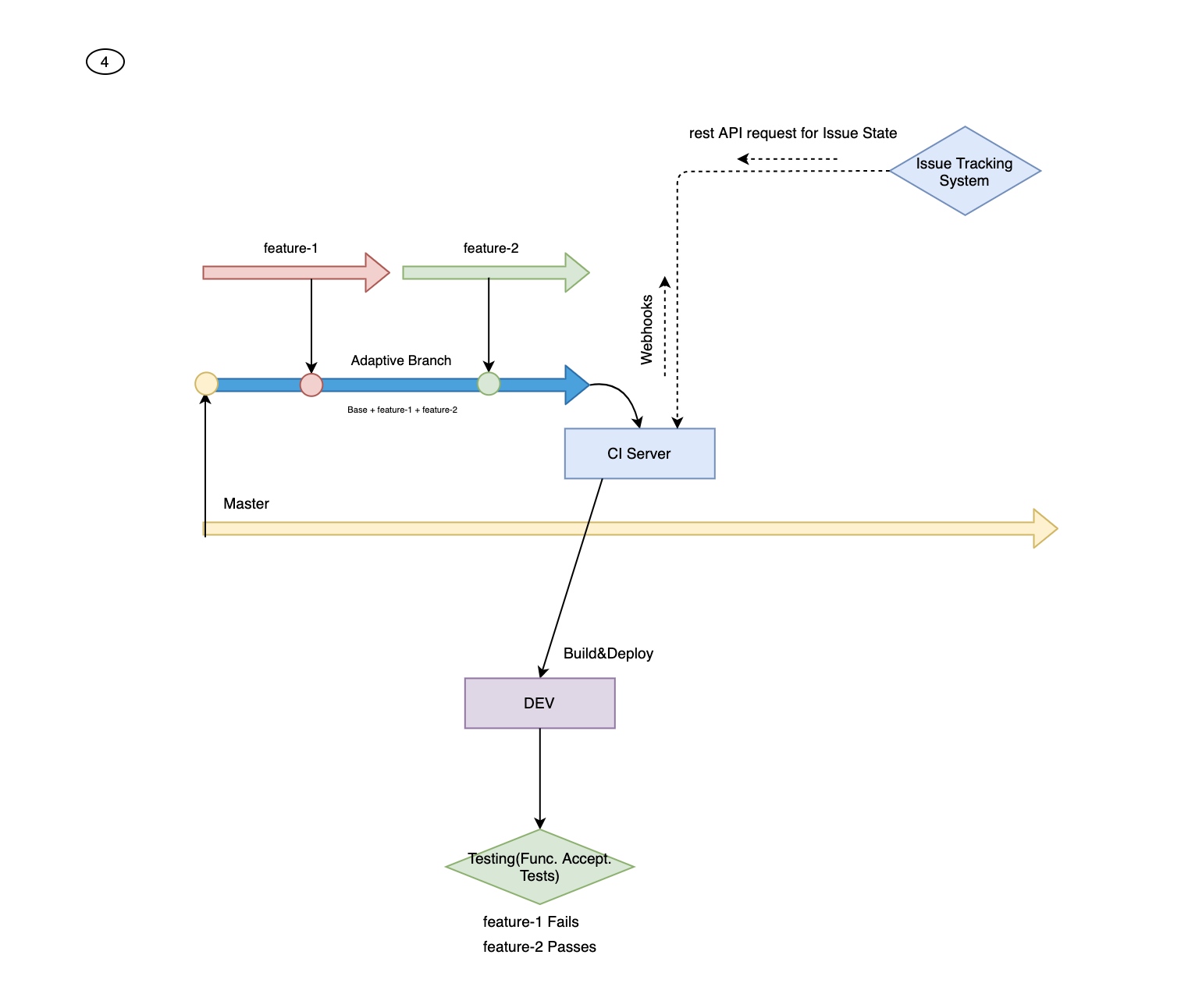
Step 4: In this step, the artifact is deployed on a server environment where both functional and non-functional acceptance tests are run. The successful result triggers an automated merge by Continuous Integration Server to the Master branch. Failure rollbacks the Issue state from “In Test” to “In Development.”
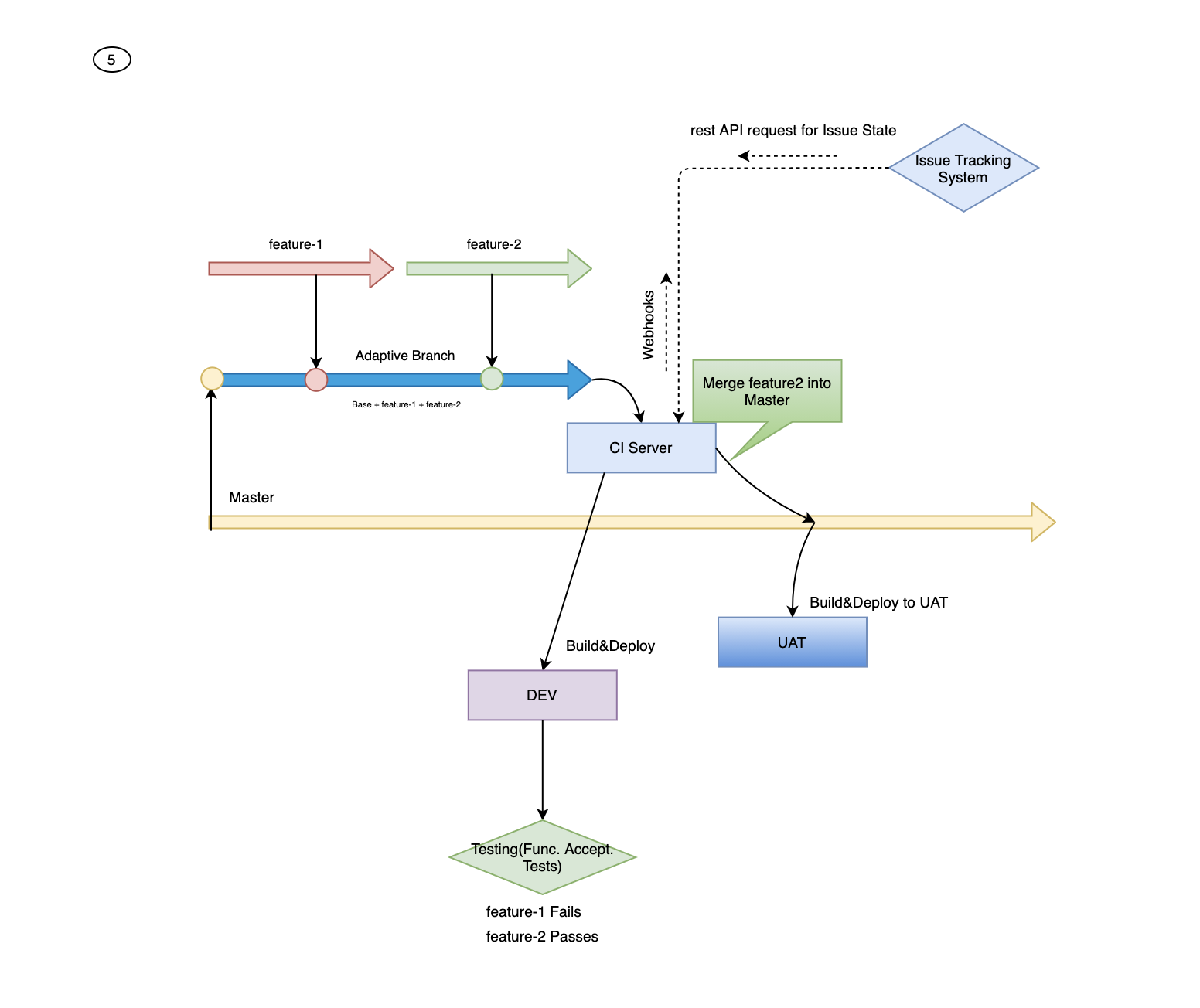
Step 5: Continuous Integration Server triggers a build from Master Branch and deploys the resulting artifact on the User Acceptance Test environment.
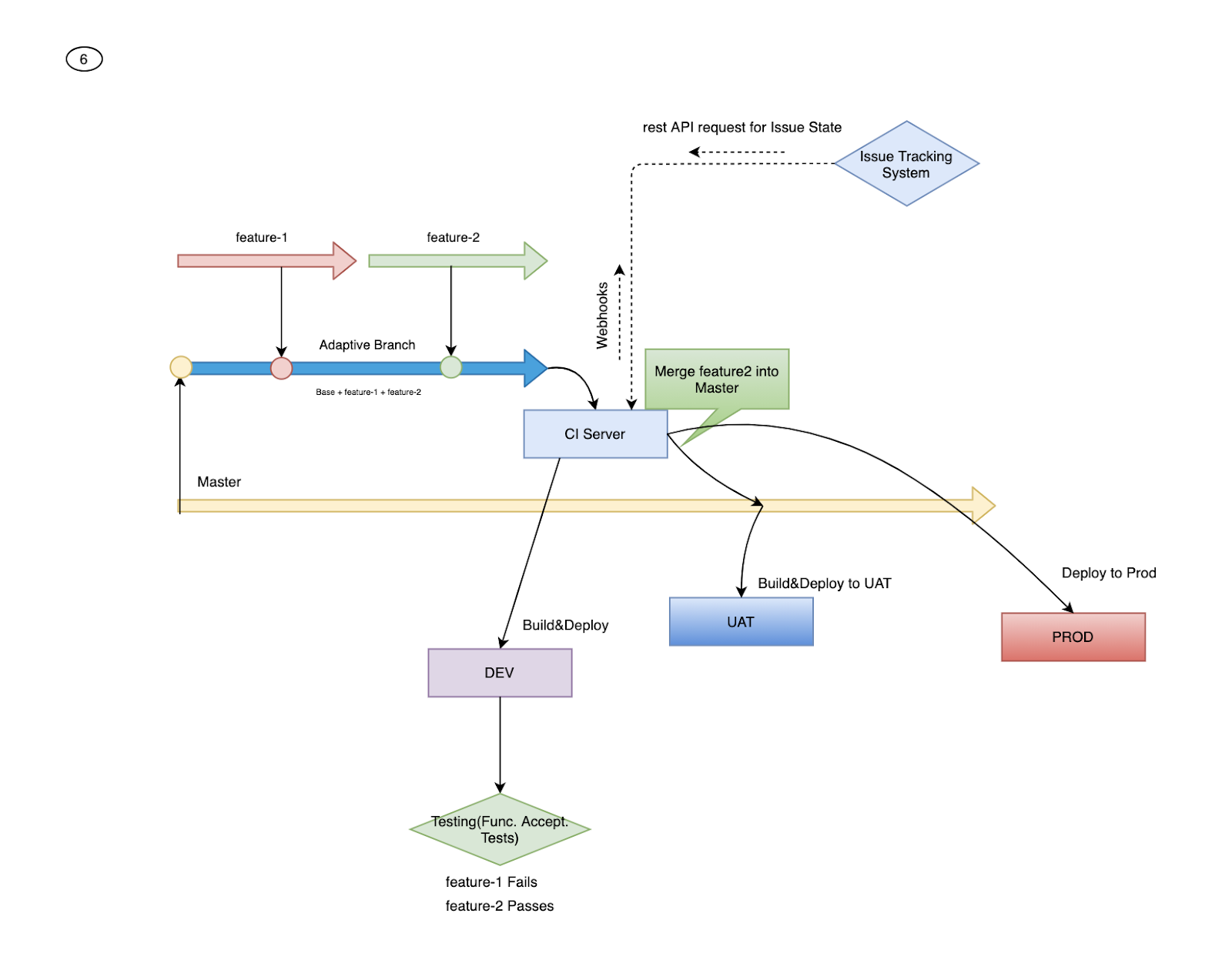
Step 6: Continuous Integration Server deploys the same artifact to the production environment.
Conclusion
This model automates the merging between several branches. Compared to environmental branches and artifacts, this model uses the same artifact with User Acceptance but sacrifices a second build compared to Trunk Based Development.