What is CDC (Change Data Capture)?
While working on a project, there may be multiple problems such as synchronizing different data sources, duplicating data and maintaining synchronization between microservices. The CDC can help us solve such problems.
Change Data Capture is a software design model used to capture and monitor change data in Databases. Thus, it can perform operations with the changed data. These operations take place in real-time.
Debezium
Debezium is an open-source platform for CDC built on top of Apache Kafka.
Debezium reads the transaction logs in the database, when there is a change, these events can be carried by stream services such as Kafka and consumed by another system. It reads the transaction logs and sends them to Apache Kafka. In case of any stop, restart or downtime, it consumes all missed events again.
Also, Debezium supports multiple datastores and Debezium can be used in systems as Embedded or Distributed.
Debezium Architecture
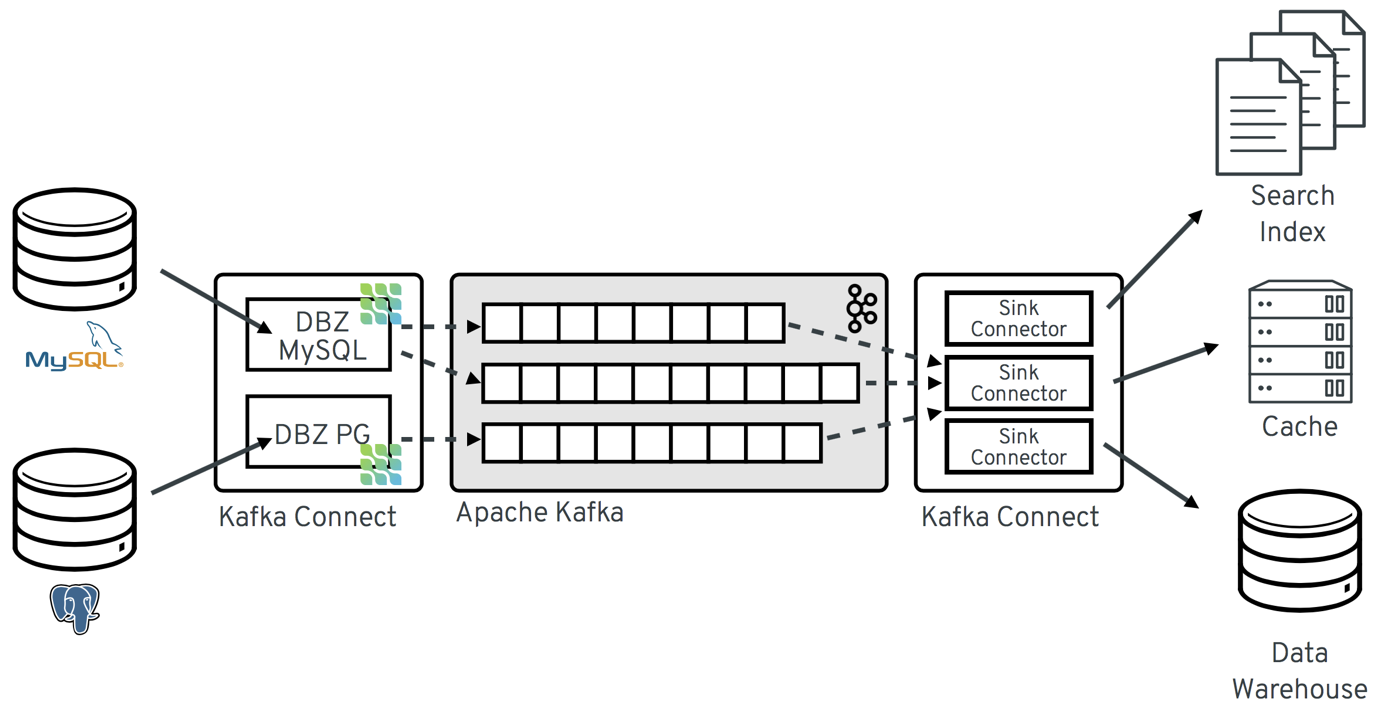
Most commonly, you deploy Debezium by means of Apache Kafka Connect. The architecture simply consists of two connectors; Sink and Source. The Source Connector reads the data from the transaction logs and sends the incoming record to Kafka. Sink connectors, on the other hand, are connected to another system, receive the event from the Kafka and operate through this event in the system it is connected to.
Source connectors are officially available in Debezium.(Connectors)
Why use Debezium?
- When synchronous updating of a database and another system is desired, it must be consistent in both systems. If the operation fails in the system, it is expected to fail in the other system. Failure of the operation on the system causes the system to be inconsistent.
- As another solution, the cost will increase when a Scheduler structure does set up. In addition, it is necessary to run the scheduler at short intervals. Here, too, there may be a consistency problem.
By using Debezium such problems can be minimized.
Let's think of another sample. There is a service, it has no API and has to be used somehow. For this, by using the debezium, the records from the other source service can be sent to the message queue and processed in this service.
Outbox Pattern with Debezium
When there is asynchronous communication between microservices, it is important to ensure that the sent messages are transmitted, prevent data loss and ensure consistency between data. The Outbox pattern is an approach for executing these transactions safely and consistently.
Simply, when a CRUD operation arrives and these events need to be dispatched, it does so within the same transaction. Write these events into an outbox table. A relay reads these events and forwards them to other services via the message broker.
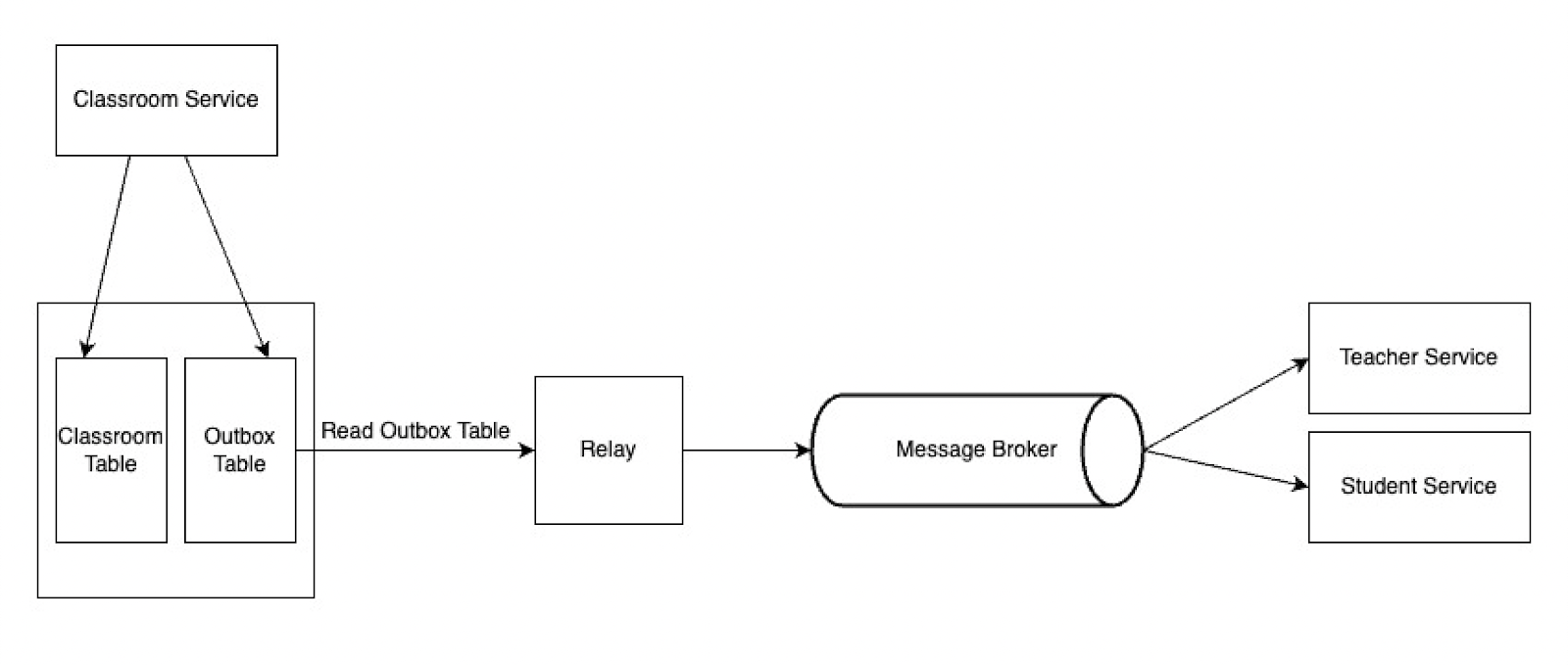
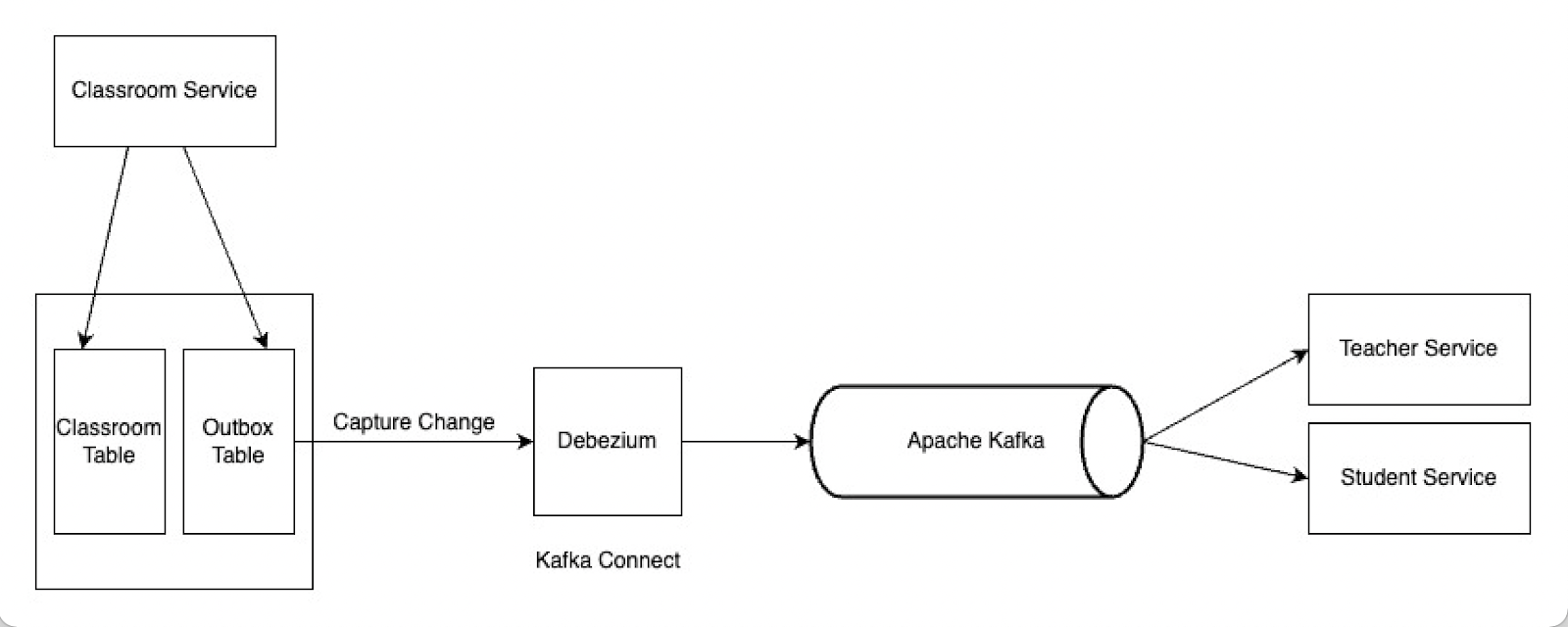
This architecture can be implemented in different ways. When we do this with Debezium, Debezium will do the relay duty here. It will receive events written to the Outbox table with Kafka connect and send them to Apache Kafka. Other services will consume these events via Apache Kafka.
Embedded Debezium
Fault tolerance and reliability may not be desired in some applications. Instead, those applications may want to place Debezium connectors directly within the application area. It can be requested to write directly to the other system instead of staying permanently in Kafka. In such cases, Debezium connectors can be configured very easily using the Debezium engine and the provided API can be used.
In the example below, data will be transferred from Postgres to Redis.
First, Debezium dependencies are added in pom.xml.
io.debezium
debezium-api
1.4.2.Final
io.debezium
debezium-embedded
1.4.2.Final
io.debezium
debezium-connector-postgres
1.4.2.Final
Basically, you create the EmbeddedEngine with a configuration file that defines the environment for both the engine and the connector.
@Bean
public io.debezium.config.Configuration authorConnector() {
return io.debezium.config.Configuration.create()
.with("name", "author-connector")
.with("connector.class", "io.debezium.connector.postgresql.PostgresConnector")
.with("offset.storage", "org.apache.kafka.connect.storage.FileOffsetBackingStore")
.with("offset.storage.file.filename", "/tmp/offsets.dat")
.with("offset.flush.interval.ms", "60000")
.with("database.hostname", host)
.with("database.port", port)
.with("database.user", username)
.with("database.password", password)
.with("database.dbname", database)
.with("database.include.list", database)
.with("include.schema.changes", "false")
.with("database.server.name", "author-server")
.with("database.history", "io.debezium.relational.history.FileDatabaseHistory")
.with("database.history.file.filename", "/tmp/dbhistory.dat")
.build();
}
The Kafka Connector class to be extended is defined in the connector.class field. Here is the usage for Postgres.
When the Kafka Connect connector runs, it reads information from the source and periodically records "offsets" that define how much of that information it processes. If the connector is restarted, it uses the last recorded offset to know where it should continue reading in the source information.
FileOffsetBackingStore specifies the class to be used to store offsets.
/tmp/offsets.dat path to save offsets.
After the configuration is complete, we create the Engine.
public DebeziumListener(Configuration authorConnectorConfiguration, AuthorService authorService) {
this.debeziumEngine = DebeziumEngine.create(ChangeEventFormat.of(Connect.class))
.using(authorConnectorConfiguration.asProperties())
.notifying(this::handleChangeEvent)
.build();
this.authorService = authorService;
}
The EmbeddedEngine is designed to be executed asynchronously by an Executor or ExecutorService.
private final Executor executor = Executors.newSingleThreadExecutor();
@PostConstruct
private void start() {
this.executor.execute(debeziumEngine);
}
@PreDestroy
private void stop() throws IOException {
if (this.debeziumEngine != null) {
this.debeziumEngine.close();
}
}
Engine created via Configuration file sends all data change to handleChangeEvent(RecordChangeEvent SourceRecord>) method. In this method, the incoming record is modified as desired to use and data is sent for processing in Redis.
private void handleChangeEvent(RecordChangeEvent sourceRecordChangeEvent) {
SourceRecord sourceRecord = sourceRecordChangeEvent.record();
Struct sourceRecordChangeValue = (Struct) sourceRecord.value();
if (sourceRecordChangeValue != null) {
Operation operation = Operation.forCode((String) sourceRecordChangeValue.get(OPERATION));
if (operation != Operation.READ) {
String record = operation == Operation.DELETE ? BEFORE : AFTER;
Struct struct = (Struct) sourceRecordChangeValue.get(record);
Map<string, string=""> payload = struct.schema().fields().stream()
.map(Field::name)
.filter(fieldName -> struct.get(fieldName) != null)
.map(fieldName -> Pair.of(fieldName, String.valueOf(struct.get(fieldName))))
.collect(toMap(Pair::getKey, Pair::getValue));
this.authorService.replicateData(payload, operation);
}
}
}
</string,>
NOTE: In case of any error, incoming data cannot be saved and queues other data for processing. In this case, consistency with the database cannot be achieved.
SUMMARY: This blog post tried to give information about CDC and the relationship between Debezium and CDC in general terms. Debezium architecture was mentioned, in what situations we should use it and information about the use of Embedded Debezium was given. Debezium's Distributed usage will be explained in the next blog post.
https://github.com/kloia/debezium-embedded
References:
https://debezium.io/documentation/reference/stable/development/engine.html
https://debezium.io/documentation/reference/stable/architecture.html